How to save 13¢ per day

Remember the good old days of recording the radio 25+ years ago? The below is an example of how to record the radio in the year 2015. This approach can be accomplished using pretty much any *nix like host. A LAMP stack (or FEMP stack in my preference) is used to re-host the podcast. Tutorials on setting up LAMP or FEMP stacks are a dime a dozen and out of scope.
First we need to find a webpage of a radio station that streams the show for which we’re looking. Then we need to find the source of the media. There are at least a 3 ways to do this. We can view the webpage source, follow and decipher various cross site javascript functions. That’s rather cumbersome. A protocol analyzer can be used to view traffic on the wire but conceivably the stream may not always be on the same host/IP. Finally we can reverse engineer the webpage using chrome’s (or firefox’s) developer tools to see what resources the webpage / browser are pulling. I chose the last of the 3 as it is quick convenient and a bit higher level.
Upon opening chrome’s developer tools window, navigating to the network tab and filtering in only media resources in the inspector window we can see what media resources are being pulled. Since this resource is going to be streaming live in perpetuity we can expect the transfer to never finish. On this webpage there is only one transfer that matches the aforementioned criteria. Chrome even notes “CAUTION: request is not finished yet!”. The ever increasing blue network transit time bar is also a dead give away. Apparently developer tools are useful for things other than circumventing ad blocker blockers.
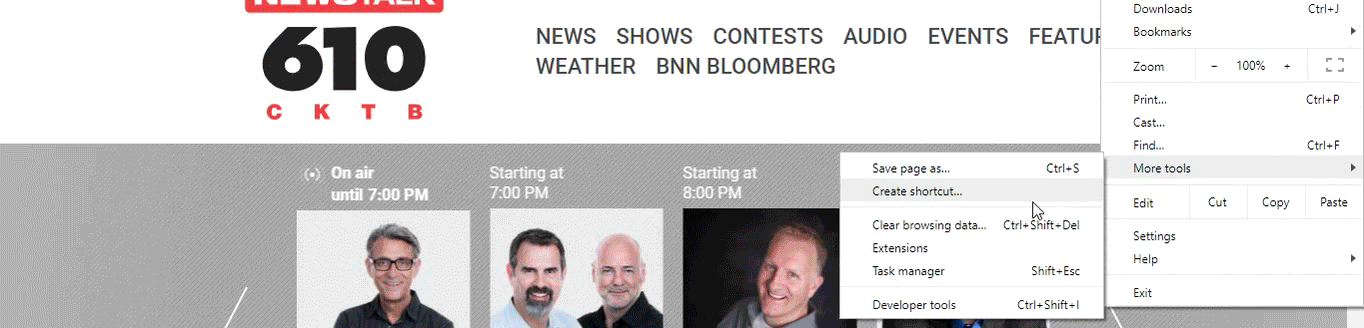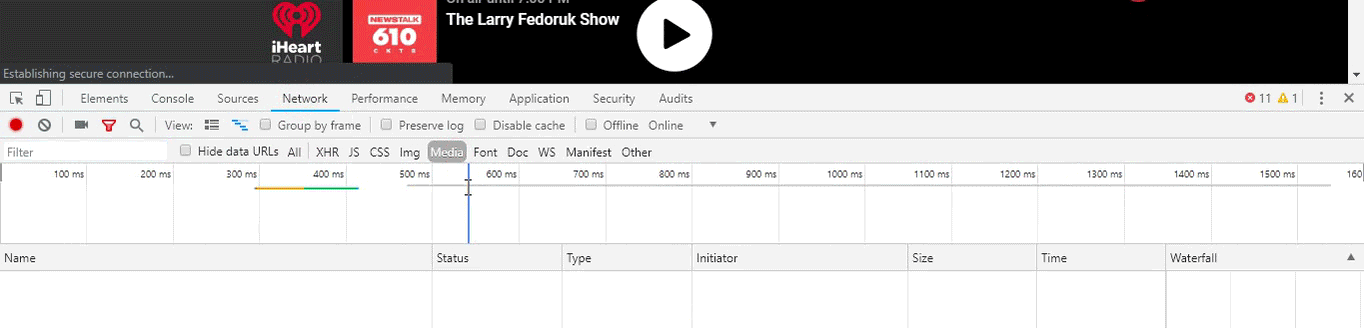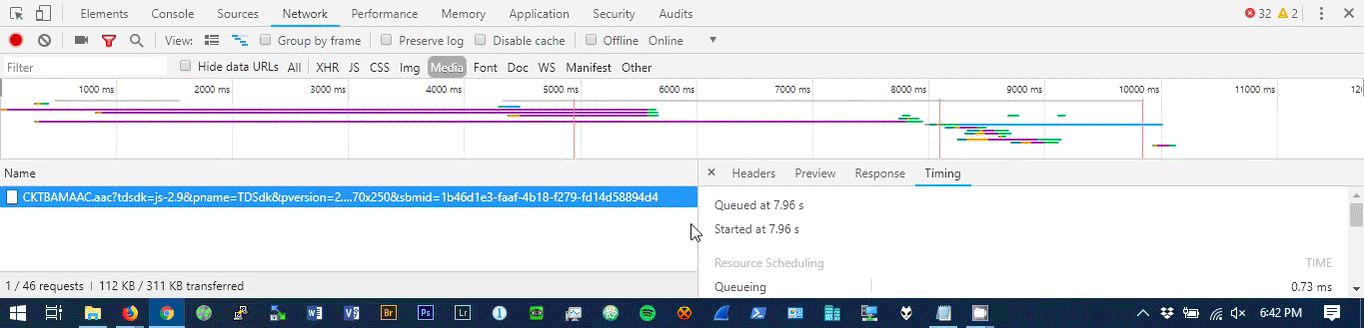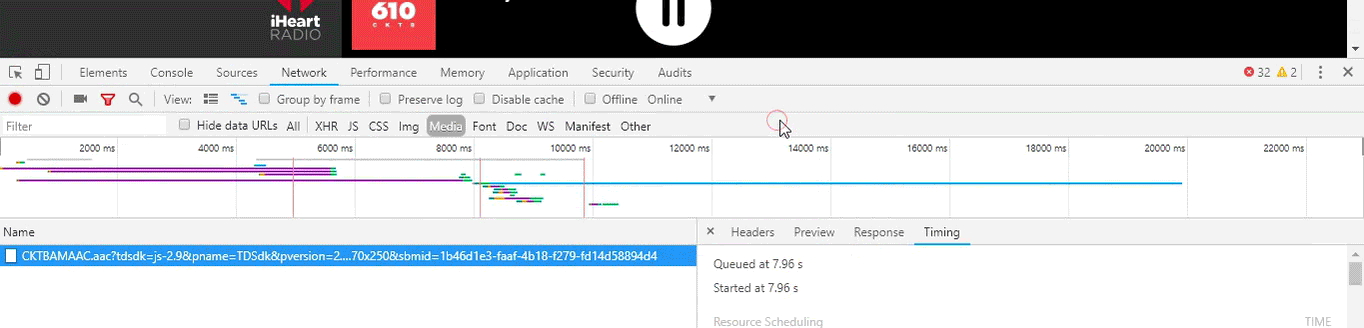
The media from the above captured URL can then be harvested using a multitude of command line tools including ffmpeg, cvlc and even wget or curl. wget and curl maybe the simplest, easiest and most foolproof but cvlc is probably the way to go as it will parse and follow the links if the server provides data in an m3u format. These commands can be wrapped in a nice start stop bash script which can be called from cron. It’s probably not very portable as it runs nightly on a FreeBSD VM and uses FreeBSD specific paths. It can be started using ctkbam.sh start and stopped using cktbam.sh stop. When stopped the resulting .mp3 will be scp’d to a remote repository. In order to use automated scp functionality shared ssh keys will have to be setup. The explanation on how to do this is also out of scope.
Coast to Coast shows are available behind a paid podcast RSS feed. The feed itself is not protected, only the audio content. Since we’re going to be re-hosting a private podcast feed for personal use we can even use curl to harvest the RSS XML and obtain episode descriptions. In ctkbam.sh xmllint is used to select the XML child elements containing the information relevant the newest published episode. A corresponding .xml file containing this information is copied over to the same repository.
#!/usr/sbin/env bash
UDATE=`date +"%s"`
YUDATE=$(($UDATE - 86400))
DATE=`date -r $YUDATE +"%Y-%m-%d"`
SAVEPATH="/tmp"
SAVEFILE=$SAVEPATH/c2c-cktbam-$DATE.mp3
XMLFILE=$SAVEFILE.xml
SCPPATH="adrian@nas00:/z/media/CoastToCoastAM"
URL="http://opml.radiotime.com/Tune.ashx?id=s31294"
RSSURL="http://feeds2.feedburner.com/C2C-PastShows"
PIDFILE="/tmp/cktbam.pid"
if [ "$1" = "start" ]; then
if [ -e $PIDFILE ]; then
echo "Found $PIDFILE, run $1 stop first."
exit 1
fi
if [ -e $SAVEFILE ]; then
echo "Save file exists, refusing to run!"
exit 2
fi
/usr/local/bin/cvlc --sout="#duplicate{dst=std{access=file,acodec=mp3,ab=48,mux=mp3,dst='$SAVEFILE'},dst=nodisplay}" $URL &
echo $! >$PIDFILE
elif [ "$1" = "stop" ]; then
if [ ! -e $PIDFILE ]; then
echo "Didnt find $PIDFILE, run $1 start first."
exit 2
fi
pkill -9 -F $PIDFILE
rm $PIDFILE
scp $SAVEFILE $SCPPATH && rm $SAVEFILE
/usr/local/bin/curl -s $RSSURL | /usr/local/bin/xmllint --xpath '(//rss/channel/item)[1]' - > $XMLFILE
scp $XMLFILE $SCPPATH && rm $XMLFILE
else
echo "usage: $0 start or stop"
fiNext a CGI script is required to generate the RSS XML feed. The below php script will scan it’s working directory for those .xml files, parse the content and present the contained episode information along with the mp3 URL to generate the feed. All that’s left to do is find a fancy logo on images.google.com to use as our feed URL.
<?php
error_reporting(E_ALL ^ E_WARNING ^ E_NOTICE ^ E_STRICT);
/*
Runs from a directory containing files to provide an
RSS 2.0 feed that contains the list files.
*/
$feedName = "Coast to Coast AM Mirror";
$feedDesc = "Coast to Coast AM Mirror";
$feedPIC = "logo.png";
$feedURL = "http://" . $_ENV["HTTP_HOST"] . dirname($_ENV["DOCUMENT_URI"]) . "/";
$feedBaseURL = $feedURL; // must end in trailing forward slash (/).
$allowed_ext = array("xml");
/* Normalize allowed extensions */
foreach ($allowed_ext as $k => $ext)
$allowed_ext[$k] = strtolower($ext);
/* List files */
$filenames = array();
$dir = opendir("./");
while (($fn = readdir($dir)) !== false)
{
$path_info = '';
$ext = '';
$path_info = pathinfo($fn);
$ext = strtolower($path_info['extension']);
if (in_array($ext, $allowed_ext))
$filenames[] = $fn;
}
closedir($dir);
/* Sort files */
natcasesort($filenames);
$filenames = array_reverse($filenames);
/* Read in xml */
libxml_use_internal_errors(true);
$podcasts = array();
foreach ($filenames as $fn)
{
$podobj = '';
$fn = rtrim($fn, '.xml');
$fc = file_get_contents($fn . '.xml');
$fc = str_replace('&', '&', $fc);
$xml = simplexml_load_string("$fc");
if ($xml === false)
foreach (libxml_get_errors() as $err)
trigger_error($err->message);
$xml[0]->description = html_entity_decode($xml[0]->description);
$xml[0]->description = strip_tags($xml[0]->description);
$podobj->title = $xml[0]->title;
$podobj->pubdate = $xml[0]->pubDate;
$podobj->description = $xml[0]->description;
$podobj->link = $feedBaseURL . $fn;
$podobj->guid = $podobj->link;
$podcasts[] = $podobj;
}
/* Output */
header('Content-type: text/xml');
echo '<?xml version="1.0" encoding="UTF-8"?>';
?>
<rss version="2.0" xmlns:atom="http://www.w3.org/2005/Atom">
<channel>
<title><?=$feedName?></title>
<link><?=$feedURL?></link>
<description><?=$feedDesc?></description>
<image>
<url><?=$feedURL . $feedPIC?></url>
</image>
<atom:link href="http://gogglesoptional.com/bloopers" rel="self" type="application/rss+xml" />
<?php
foreach ($podcasts as $pc)
{
echo "<item>",
" <title>". $pc->title ."</title>",
" <description>". $pc->description . "</description>",
" <link>". $pc->link . "</link>",
" <pubDate>". $pc->pubdate . "</pubDate>",
" <guid>". $pc->link . "</guid>",
"</item>" . "\n";
}
?>
</channel>
</rss>Finally schedule everything to run with cron;
adrian@vmm02:~$ crontab -l
00 1 * * * /usr/home/adrian/.bin/cktbam.sh start
00 5 * * * /usr/home/adrian/.bin/cktbam.sh stopAdd in the feed URL to the podcast app of your choice and George Noorie’s your uncle! Of course the official coast to coast am podcast feed can be subscribed to for 13 cents per day.